Unit 2.3 (Extracting Information from Data, Pandas) Notes
Data connections, trends, and correlation. Pandas is introduced as it could be valuable for PBL, data validation, as well as understanding College Board Topics.




- Pandas and DataFrames
- Cleaning Data
- Extracting Info
- Create your own DataFrame
- Example of larger data set
- APIs are a Source for Writing Programs with Data
- Hacks
Pandas and DataFrames
In this lesson we will be exploring data analysis using Pandas.
- College Board talks about ideas like
- Tools. "the ability to process data depends on users capabilities and their tools"
- Combining Data. "combine county data sets"
- Status on Data"determining the artist with the greatest attendance during a particular month"
- Data poses challenge. "the need to clean data", "incomplete data"
- From Pandas Overview -- When working with tabular data, such as data stored in spreadsheets or databases, pandas is the right tool for you. pandas will help you to explore, clean, and process your data. In pandas, a data table is called a DataFrame.
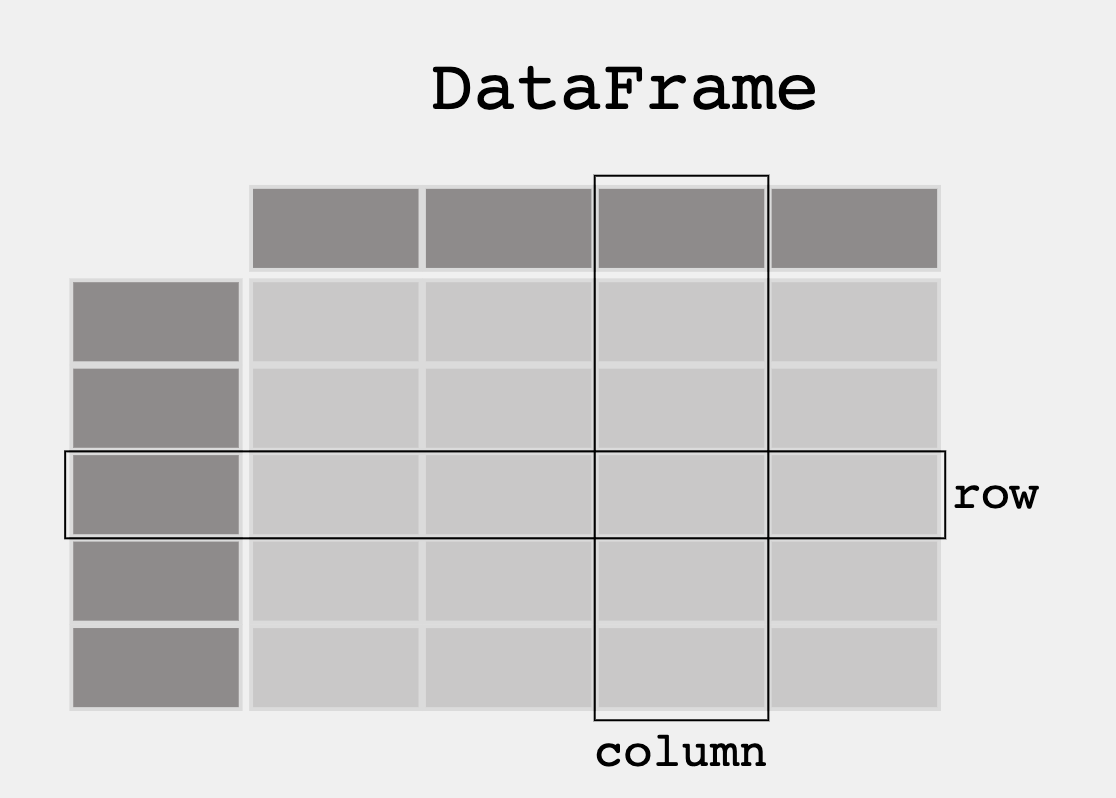
'''Pandas is used to gather data sets through its DataFrames implementation'''
import pandas as pd
df = pd.read_json('files/grade.json')
print(df)
# What part of the data set needs to be cleaned?
# From PBL learning, what is a good time to clean data? Hint, remember Garbage in, Garbage out?
print(df[['GPA']])
print()
#try two columns and remove the index from print statement
print(df[['Student ID','GPA']].to_string(index=False)) #HOW TO HIDE INDEX, FOR LATER
print(df.sort_values(by=['GPA']))
print()
#sort the values in reverse order
print(df.sort_values(by=['GPA'], ascending=False))
print(df[df.GPA > 3.00])
print(df[df.GPA == df.GPA.max()])
print()
print(df[df.GPA == df.GPA.min()])
import pandas as pd
#the data can be stored as a python dictionary
dict = {
"calories": [420, 380, 390, 300],
"duration": [50, 40, 45, 35] #I added new values
}
#stores the data in a data frame
print("-------------Dict_to_DF------------------")
df = pd.DataFrame(dict)
print(df)
print("----------Dict_to_DF_labels--------------")
#or with the index argument, you can label rows.
df = pd.DataFrame(dict, index = ["day1", "day2", "day3", "day4"])
print(df)
print("-------Examine Selected Rows---------")
#use a list for multiple labels:
print(df.loc[["day1", "day3"]])
#refer to the row index:
print("--------Examine Single Row-----------")
print(df.loc["day1"])
print(df.info()) #prints with new data set in mind
import pandas as pd
#read csv and sort 'Duration' largest to smallest
df = pd.read_csv('files/data.csv').sort_values(by=['Duration'], ascending=False)
print("--Duration Top 10---------")
print(df.head(10))
print("--Duration Bottom 10------")
print(df.tail(10))
'''Pandas can be used to analyze data'''
import pandas as pd
import requests
def fetch():
'''Obtain data from an endpoint'''
url = "https://flask.nighthawkcodingsociety.com/api/covid/"
fetch = requests.get(url)
json = fetch.json()
# filter data for requirement
df = pd.DataFrame(json['countries_stat']) # filter endpoint for country stats
print(df.loc[0:5, 'country_name':'deaths']) # show row 0 through 5 and columns country_name through deaths
fetch()
Hacks
Early Seed award
I hope you saw it during class.
AP Prep
I didn't make my own questions this time because I learned that we weren't really intended to do that. I did take the College Board practice quiz, though.
2.3 College Board Practice Problems
Here are the results of the 2.3 practice questions.

All of the questions had very clear answers, so I don't have a lot to reflect on. They were common sense questions above all else.
Personal Dataset Work
The next 4 weeks, Teachers want you to improve your understanding of data. Look at the blog and others on Unit 2. Your intention is to find some things to differentiate your individual College Board project.
-
Create or Find your own dataset. The suggestion is to use a JSON file, integrating with your PBL project would be Amazing.
-
When choosing a data set, think about the following...
- Does it have a good sample size?
- Is there bias in the data?
- Does the data set need to be cleaned?
- What is the purpose of the data set?
- ...
-
Continue this Blog using Pandas extract info from that dataset (ex. max, min, mean, median, mode, etc.)
I decided to try applying Pandas sorting methods to my events database from the Cafe Gato project.
'''Pandas can be used to analyze data'''
import pandas as pd
import requests
def fetch():
global eventdf
'''Obtain data from an endpoint'''
url = "https://cgato.duckdns.org/api/events/"
fetch = requests.get(url)
json = fetch.json()
# filter data for requirement
eventdf = pd.DataFrame(json) # filter endpoint for country stats
print(eventdf.loc[0:5, 'date':'name']) # show row 0 through 5 and columns country_name through deaths
fetch()
print(eventdf.loc[0:4, 'date':'event_name'].sort_values(by=['date'], ascending=True))
print(eventdf.loc[0:4, 'date':'event_name'].sort_values(by=['date'], ascending=False))
Other Online Data
I decided to use a free health statistics API from RapidAPI and try to see things about it with Pandas. It mostly covers the basic health information of servings of common ingredients (so not full recipe details).
It's a fairly complicated data set, so I ended up spending a while just trying to isolate important data. Below, you can see that I managed to isolate the nutrition information.
import pandas as pd
import requests
# GET code
url = "https://edamam-food-and-grocery-database.p.rapidapi.com/parser"
querystring = {"ingr":"apple"}
headers = {
"X-RapidAPI-Key": "f9dc4c060fmsh192fef0e86699c6p109981jsn882369c51285",
"X-RapidAPI-Host": "edamam-food-and-grocery-database.p.rapidapi.com"
}
response = requests.request("GET", url, headers=headers, params=querystring)
json = response.json()
nutrients = json['parsed'][0]['food']['nutrients']
#fooddf = pd.DataFrame(json[1]['nutrients'])
#print(fooddf)
print(nutrients)
The data above is only for "apple," however. I decided to try to expand the amount of data by removing the querystring.
In order to translate the acronyms, I had to look at the documentation for the API to correctly label it.
import pandas as pd
import requests
# GET code
url = "https://edamam-food-and-grocery-database.p.rapidapi.com/parser"
headers = {
"X-RapidAPI-Key": "f9dc4c060fmsh192fef0e86699c6p109981jsn882369c51285",
"X-RapidAPI-Host": "edamam-food-and-grocery-database.p.rapidapi.com"
}
response = requests.request("GET", url, headers=headers) #fetch with no query
json = response.json()
fooddata = [] #for appending data here
for data in json['hints']: #reformatting the information for the pandas table
newdict = {'Name':data['food']['label'],
'Calories':data['food']['nutrients']['ENERC_KCAL'],
'Protein (g)':data['food']['nutrients']['PROCNT'],
'Fat (g)':data['food']['nutrients']['FAT'],
'Carbohydrates (g)':data['food']['nutrients']['CHOCDF'],
'Fiber (g)':data['food']['nutrients']['FIBTG']}
fooddata.append(newdict)
fooddf = pd.DataFrame(fooddata)
#print(fooddf)
Since that prints a whole lot of data, I decided to narrow it to the top five.
Here is the top five most protein-rich ingredients in the list. So that it would stay within one line, I made it cut off at 'Fat (g)'.
print(fooddf.loc[0:5, 'Name':'Fat (g)'].sort_values(by=['Protein (g)'], ascending=False))
The data that it's letting me pull is usually at the start of the aphabet. There may be more with the full, paid version of the API. This shows that some variations of cheeses have more protein than others in the full list.
Hack Helpers
To declutter my blog, I decided to delete this section since it's in the source article anyway. For my own personal reference, it can be found here.